- 趣味
ポケモンデータでPythonマスター!楽しく学ぶデータ分析の基礎


はじめまして。2023年入社の丸山です。現在はソフト開発領域分野で、クラウドサービスのバックエンド開発を行っています。そこで、よく使われているのがプログラミング言語python。Pythonは2023年、2024年にわたり使用率が高い言語ランキング1位を獲得した、今話題のプログラミング言語といえるでしょう。
ではなぜ、pythonが人気なのか。
それは、主に3つの理由が考えられます。
- 文法がやさしく初心者でも比較的簡単に読み書きできるから
- AI開発やデータ分析、機械学習のライブラリが豊富だから
- 汎用性が高いから
プログラミング初心者でも比較的簡単に手を出せて、現在はやりのAIや機械学習を試すためのアシストが豊富。今、人気な言語になるのも納得ですね。
とはいえ、プログラム初心者が一からプログラムを勉強しようしてもハードルが高い。。。
なので、今回はポケモンのデータとpythonを使用してデータ分析上「強い」ポケモンを探すことで、pythonの使い方やデータの可視化方法を学んでみたいと思います!
準備
今回準備するものは簡単に以下の通りです。
・pythonを動かせる環境
・ポケモンのデータ(https://www.kaggle.com/abcsds/pokemon)
Kaggleというサイトは「データサイエンスと機械学習の家」と題されるデータサイエンスや機械学習界隈最大規模のコミュニティです。ここでは自分の好みのデータを探したり、データを使ったコンペに参加することができるので興味があるかたは是非!また、Python環境については自分の環境で動かしやすければ特に指定はありません。Pythonのインストールが面倒という方はGoogle Colabを使うのも一つの手かなと思います。(この場合、Google アカウントが必要なところは注意)
使用データの確認
まずは使用するデータを確認しましょう。ここでは、準備したcsvファイルの中にどんなデータが入っているのか、とりあえずデータの先頭から5行の表示と分析に使用するポケモンの総数を表示するプログラムを書きます。今回はpandasモジュールを使用ました。
###分析プログラム1###
import pandas as pd # ライブラリ pandas をインポートし、以下 pd と呼ぶことにする。
# df とは、 pandas の DataFrame 形式のデータを入れる変数として命名
df = pd.read_csv("Pokemon.csv")
df.head() # 先頭5行を表示
print("分析に使用するポケモンの総数:"+str(len(df)))
print(df.head())
Pandasモジュールを使用することで簡単に可視化することができました!ここから分析に使用するポケモンが800体もいるなんて。。。ポケモンの歴史を感じます。
----pythonモジュールとpandasを使用した理由----(興味がない方は読み飛ばしてください)
pythonにはたくさんのモジュールがあり、目的に合わせてそれらを使うことができます。例えば、今回使用したpandasというモジュールはデータを効率的に扱うために開発されたモジュールの1つで、以下のような特徴があります。
pandasモジュールの特徴
- データの読み込み・書き出しが簡単
- CSV、Excel、SQL、JSONなど多様なデータ形式を簡単に読み込んだり、書き出したりできる。
- データフレームとシリーズ
- DataFrame(2次元データ)とSeries(1次元データ)というデータ構造を提供し、操作が直感的。
- データのクリーニングと前処理や集計、分析などが簡単に行える
- 欠損値の処理、重複データの削除、データ型の変換などが簡単に行える。
- 行や列の条件に基づいたデータの抽出が簡単にできる。
- グループ化や集計、ピボットテーブルの作成など、データの集計や統計処理が簡単にできる。
- データのピボット、メルト、リシェイプなど、データの形を変える操作が簡単にできる。
- 時系列データの操作
- 日付や時刻データの処理、時系列データのリサンプリングやシフトなどが簡単に行える。
- 強力な可視化機能との連携
- matplotlibやseabornといった可視化ライブラリとの連携が容易で、データの可視化が簡単にできる。
今回pandasモジュールを使用したのは、2番、3番、5番の理由が大きいです。
では分析に戻りましょう!
次に注目するところは、1匹のポケモンに対してこんなに様々な能力値の振り分けですね。Hpや'Attack'のポケモンのゲームをしたことがある人には聞きなじみの良い能力値が訳8~9個ほど振り分けられています。なので、次はポケモンごとの能力値を可視化してみます。
###分析プログラム2###
df.head().style.bar(subset=['Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed'])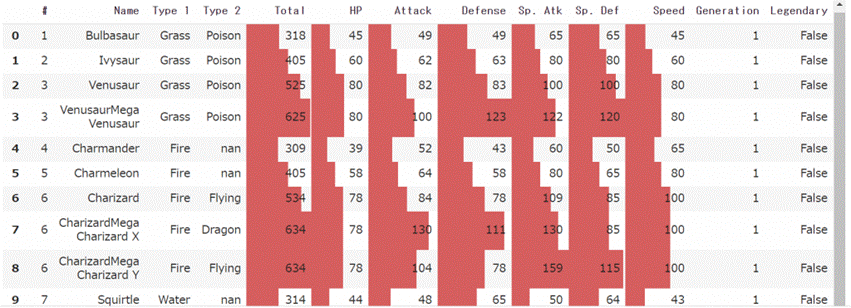
3番が2か所あって気になっていたのですが、totalの値で見ると100も違います。これはフシギバナとフシギバナ特殊進化個体であるメガフシギバナであることがわかりました。さすが特殊進化というだけであって能力値が大きく跳ね上がってます!
ポケモンの平均を求めてみよう
次に、平均値など基本的なポケモンの情報を計算してみます。データを分析するとき、平均値、標準偏差、最小値、最大値などの代表値を調べておくということが意外と大切。これしておくと全データの傾向がわかります。また、有名な代表値の特性を知っておくこともおすすめです!
例えば、平均値はざっくりとデータの真ん中を推測するときに便利ですが、外れ値の影響を受けやすいというデメリットが存在します。ほかの代表値にもメリット、デメリットがあり、分析の目的などに合わせて使用する代表値を選択することがデータ分析のカギになります。(そしてここが意外とめんどくさいです)
今回はpandasを使用しているので簡単に平均値、標準偏差、最小値、25%四分値、中央値、75%四分値、最大値を出してくれる関数を使用してみましょう。(最近のpythonモジュール簡単すぎて怖い)
###分析プログラム3####
df.describe()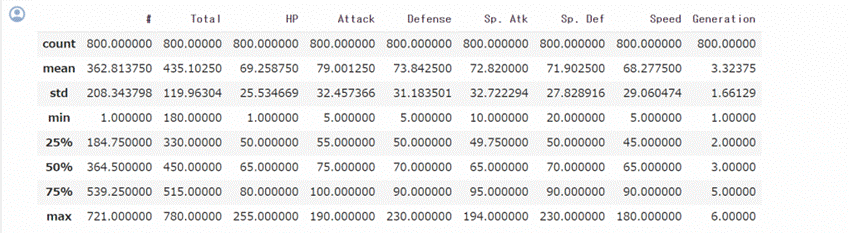
できたグラフを見てみてください!なんと、HPが1のポケモンがいることがわかりました。攻撃力(Attack)の最小値(min)が5なのでポケモンに攻撃された時点で死んでしまう。。。
ちなみにそのポケモンはヌケニン!(https://zukan.pokemon.co.jp/detail/0292)このポケモン、もちろんHPは最弱。Totalでもワースト2位という弱さだそうです。その一方、特性「ふしぎなまもり」の効果で自分の弱点以外の攻撃が無効化されるそう。ポケモンの強さの形は様々ということがわかりましたが、今回は特性のデータがないのでそこまで調べるべきか...課題も見つかり、宿題ができてしまいました...ORZ
とりあえず!!!
やっとデータの全体をザクっと系釈するとところまで終わりました。
データの入っているポケモン自体が800体もいたためここまででも結構時間がとられてしまいました。次回は散布図や相関係数を使用して、実際にポケモンに作用するつよさのパラメータを探っていこうと思います。
『ポケモン』は任天堂・クリーチャーズ・ゲームフリークの登録商標です。
