- AI基盤
Amazon Kendraとは?S3のドキュメントを自然言語で検索してみた

Amazon Kendraとは
Amazon Kendra は、機械学習を活用したAWSのAI検索サービスです。
社内に散在するドキュメントやデータを自然言語で検索できるのが特徴です。
従来のキーワード検索では、検索語と完全に一致する単語が含まれていないと目的の情報にたどり着けないことが多くありました。
一方、Kendra では文章の意味を理解した検索(セマンティック検索)が行われるため、
- 「〇〇の手順は?」
- 「△△の申請方法は?」
- 「リスクベース認証とは?」
といった曖昧な質問形式の検索でも、関連性の高い情報を見つけることができます。
今回は、実際にS3に保存したドキュメントをAmazon Kendraで検索できるようにする構成を試してみました。
Amazon Kendraを試してみる
今回は以下の構成でS3とKendra を連携します。
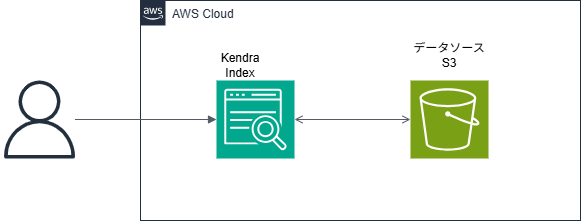
大きな流れは以下の4ステップです。
- S3にドキュメントを保存
- Kendraのインデックスを作成
- データソース(S3コネクタ)を設定
- 検索を実行
1. S3バケットにデータを保存
まずは検索対象となる文書を用意します。
Amazon Kendra は以下のようなファイル形式に対応しています。
- Word
- テキストファイル
- HTML
- PowerPoint
など
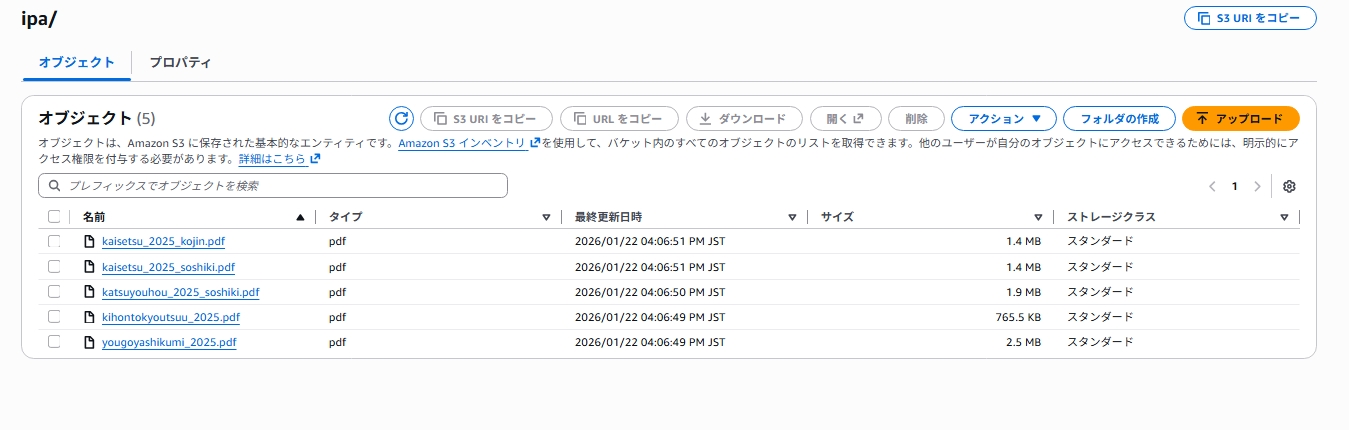
今回は以下の資料を用意しました。
- 「情報セキュリティ10大脅威2025」 … IPA公開資料のPDF
- 社内アプリのマニュアル … PowerPoint
この段階では特別な加工は不要で、既存のファイルをそのままS3にアップロードするだけで問題ありません。
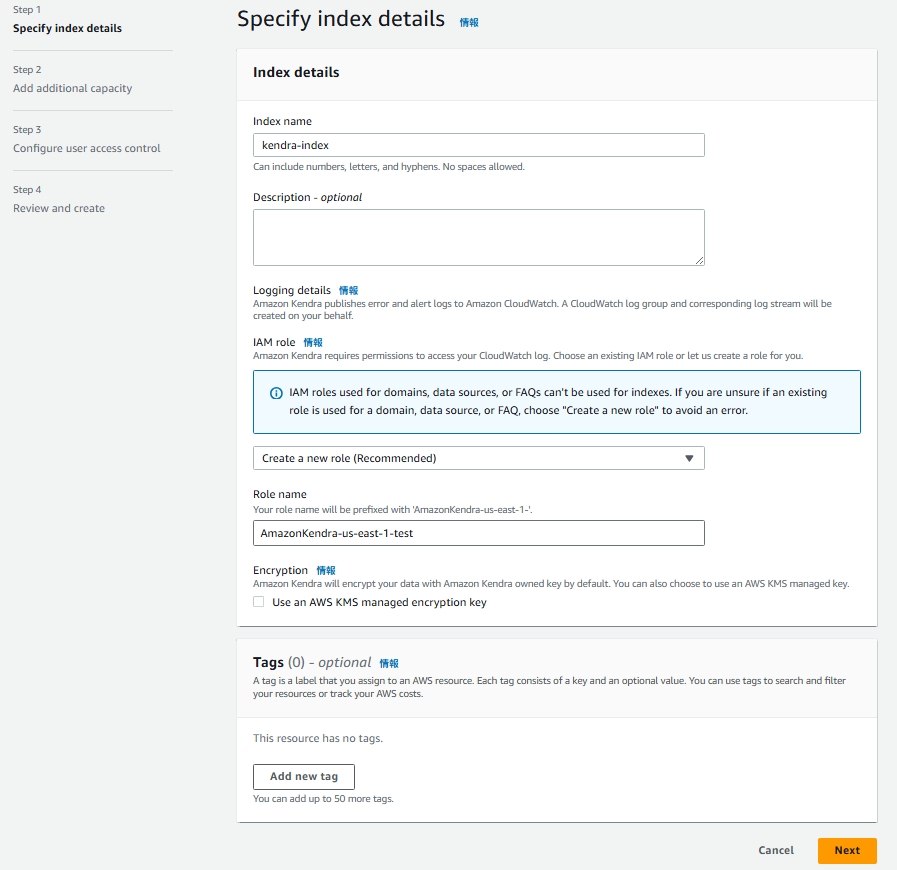
2. インデックスを作成
次にAmazon Kendraのインデックスを作成します。
Kendraにおけるインデックスとは、検索対象の文書をまとめて管理する場所のようなものです。
コンソールから以下の設定を行います。
主な設定項目
- Index name
- IAM role(Create a new role)
- Role name
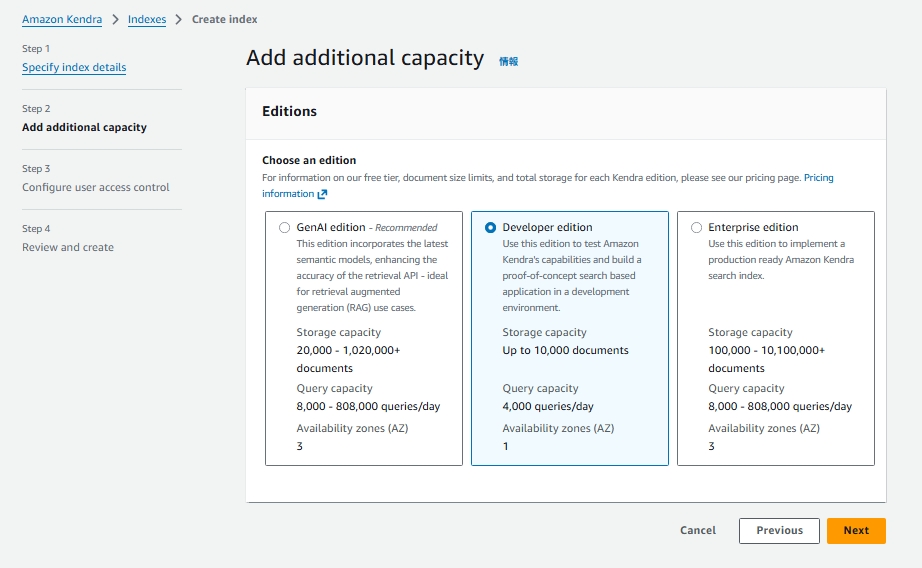
EditionsはDeveloper Editionを選択します。
その後、
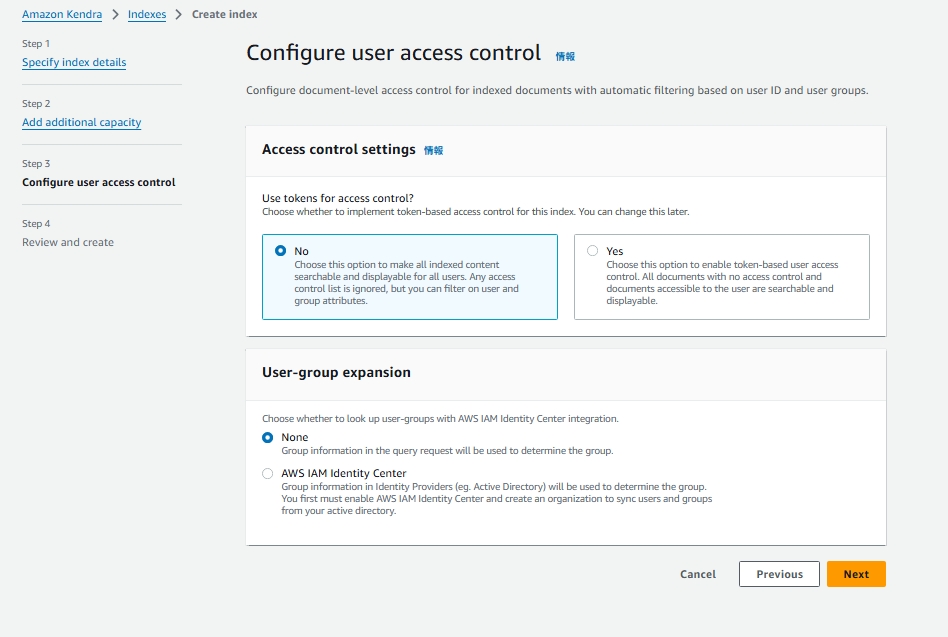
- アクセス制御(デフォルト)
- 設定確認
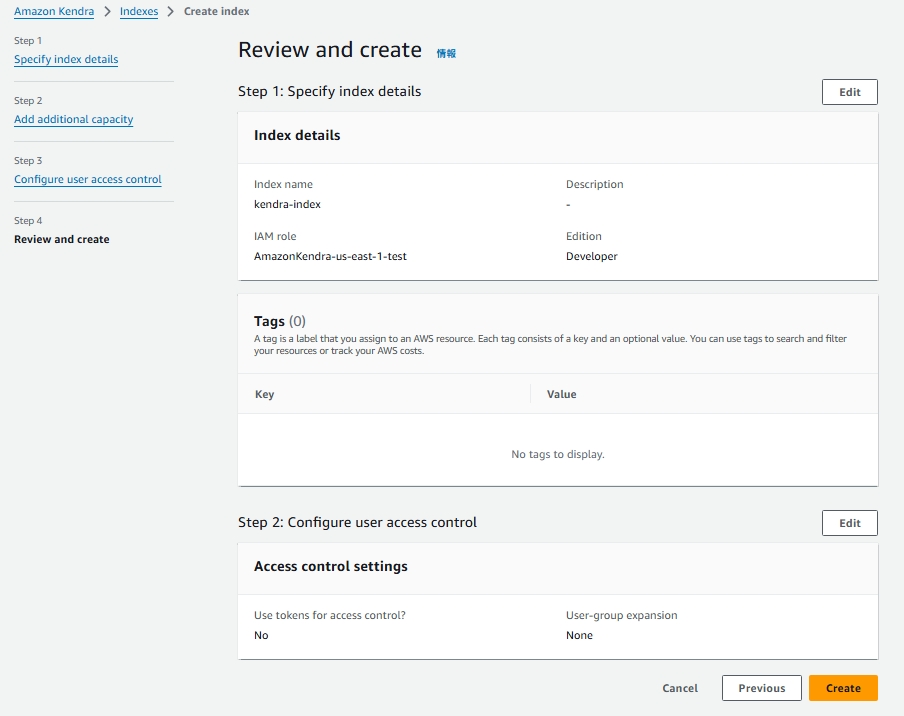
を行いCreateをクリックするとインデックスが作成されます。
3. データソースを用意(S3コネクタ)
インデックス作成後データソースを設定します。
今回はS3コネクタを使用します。
主な設定項目は以下です。
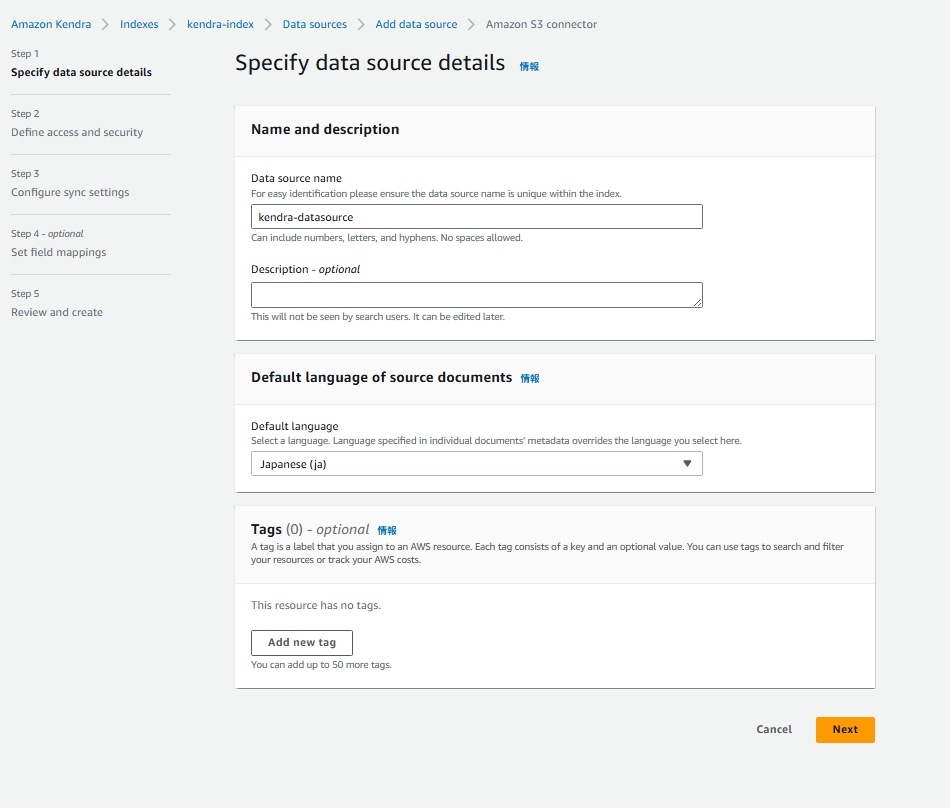
基本設定
- Data source name
- Default language → Japanese
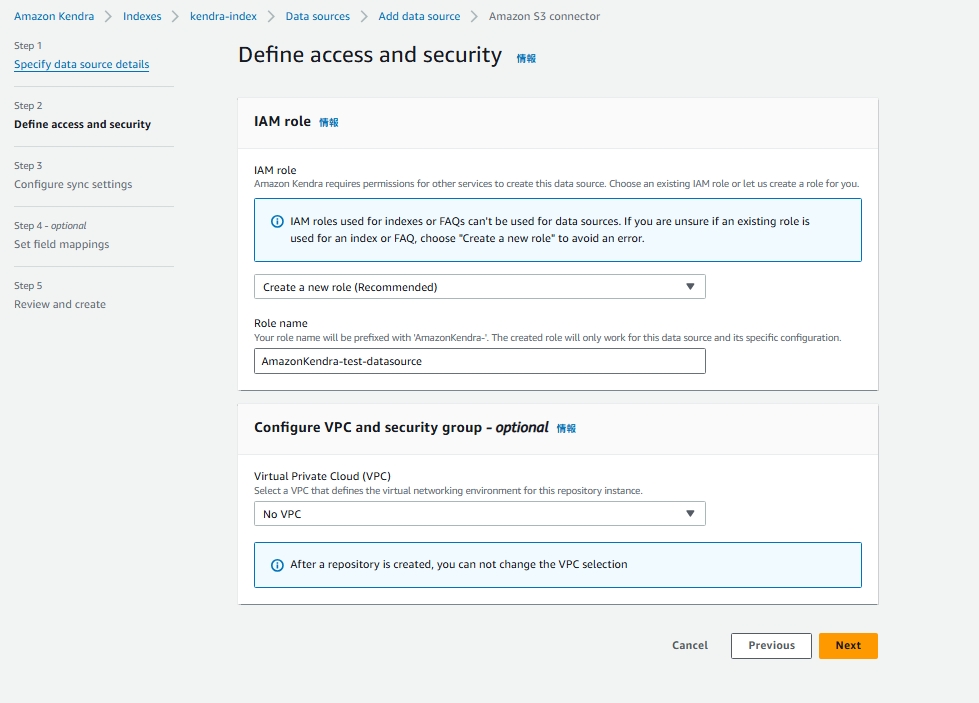
IAM設定
- IAM role(Create a new role)
- Role name
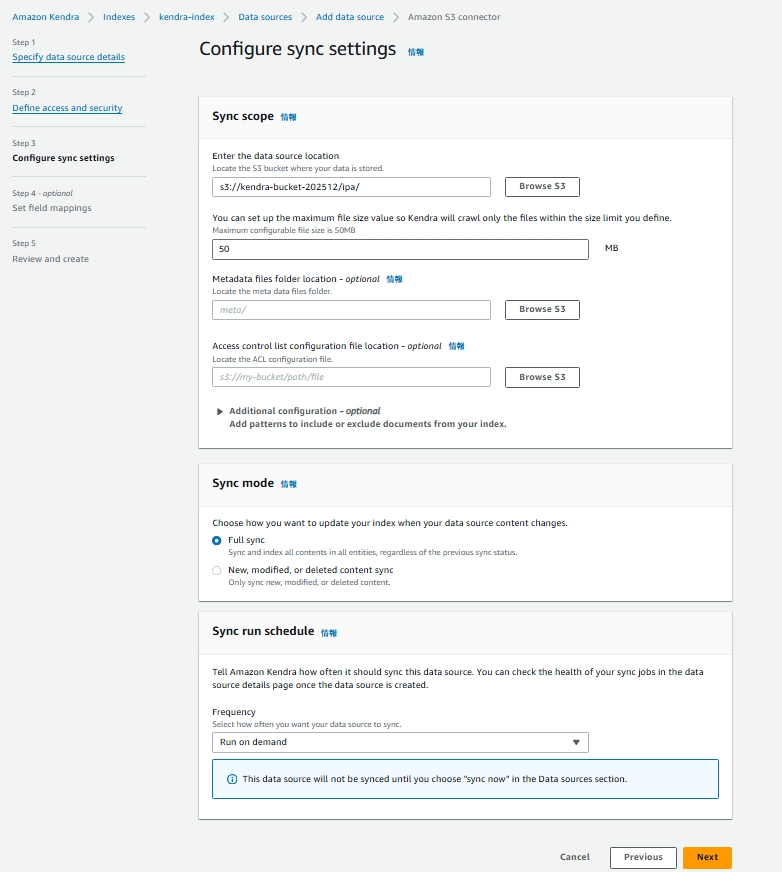
同期設定
- Enter the data source location (最初に用意したS3バケットのURI)
- Frequency (Run on demand)
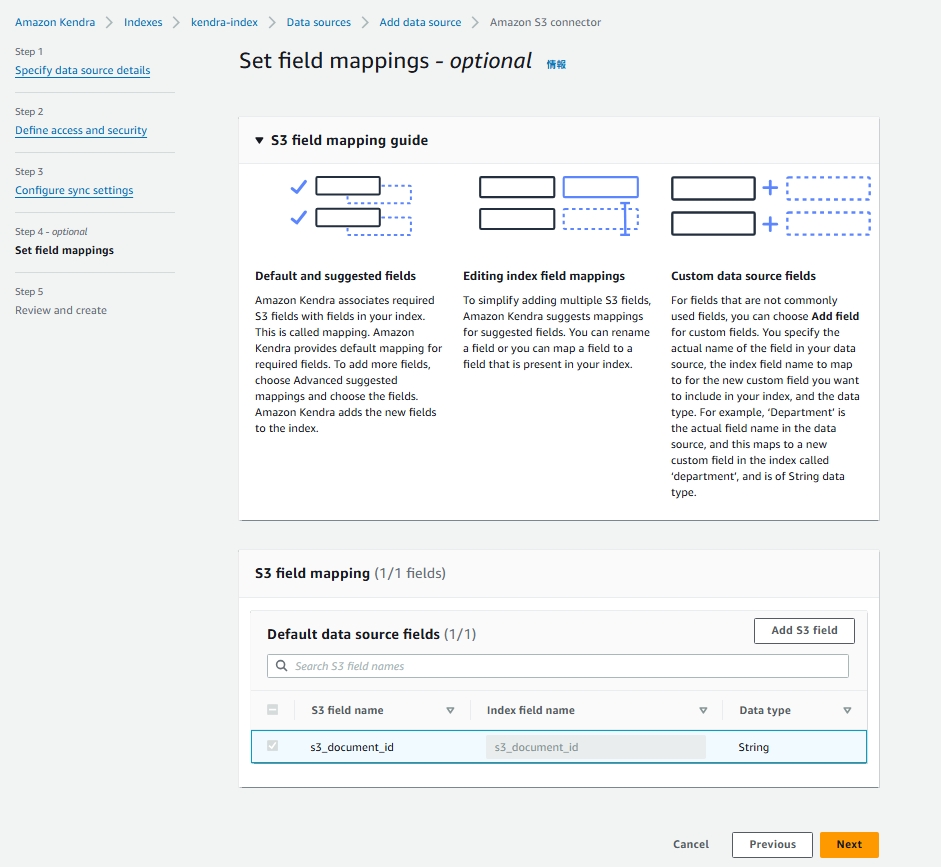
フィールドマッピング
- Set field mappings(デフォルト)
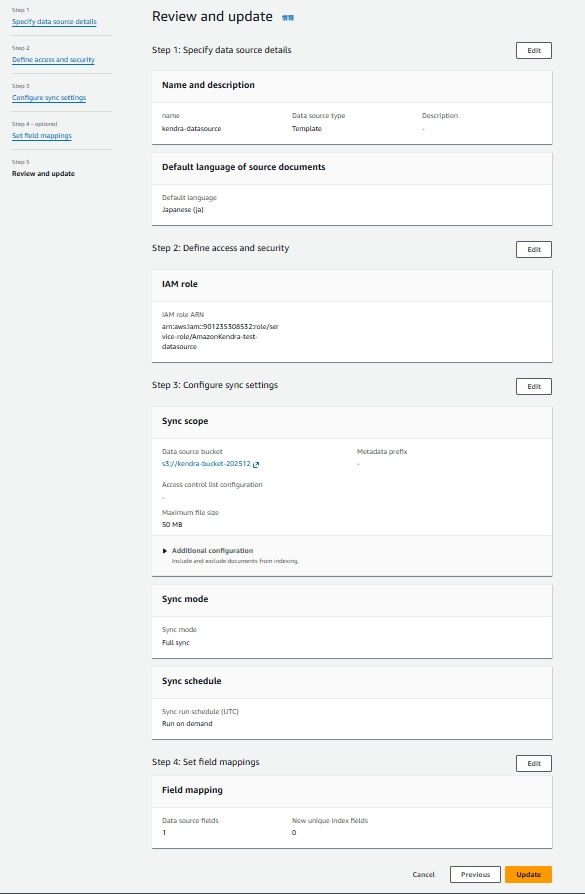
最後に設定を確認し、Add data sourceをクリックすると、データソースが追加されます。
※以下はあとから画像をスクショしたのでUpdateとなっています
補足:インデックスとデータソースの役割
Kendraでは、以下のように役割が分かれています。
- データソース → S3やSharePointなどの文書の保存場所
- インデックス → データソースの文書を取り込み、検索できる形にしたもの
Amazon Kendra では、
- S3
- SharePoint
- Confluence
- Salesforce
などの主要サービス向けにコネクタが用意されています。
そのため、既存の業務ドキュメントを比較的簡単に検索基盤へ取り込むことができます。
コネクタの詳細はこちら
https://aws.amazon.com/jp/kendra/connectors/
4. 検索してみる
データソースの同期が完了したら、実際に検索してみます。
インデックスの管理画面から「Search indexed content」をクリックします。
Settings で
Default language of source documents
→ Japanese
を設定しておきます。
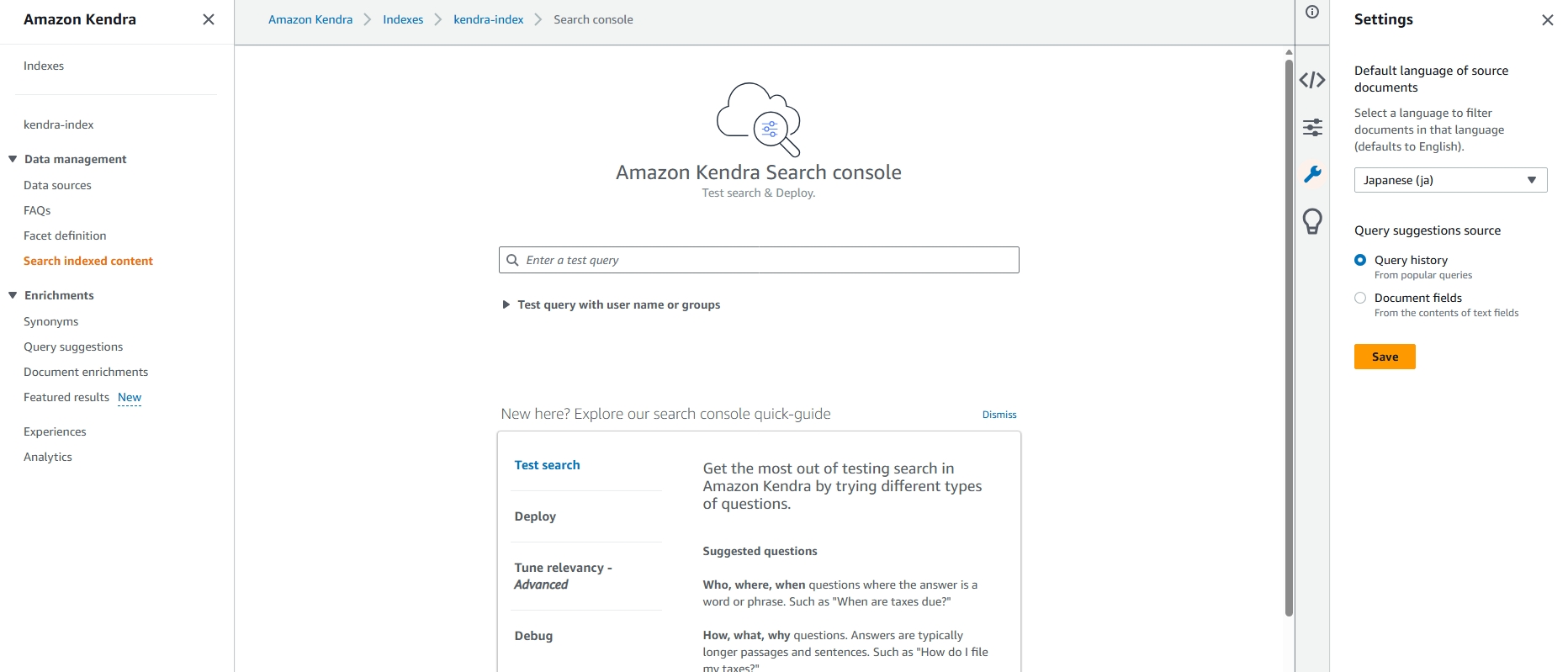
例えば次のような質問を入力します。
- リスクベース認証とは?
- ペルソナの使用例
すると、Kendra が関連する文書を検索し、該当箇所をハイライト表示した状態で結果を返してくれます。
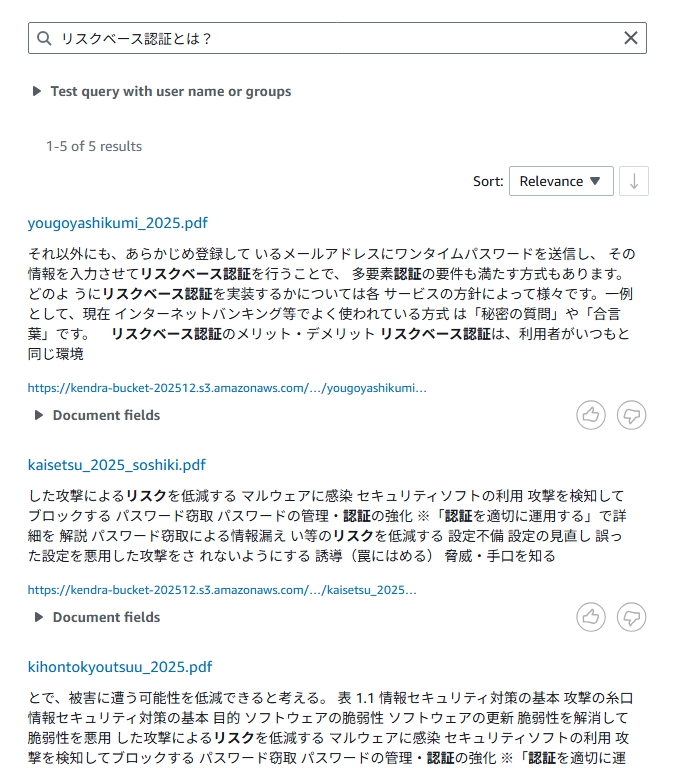
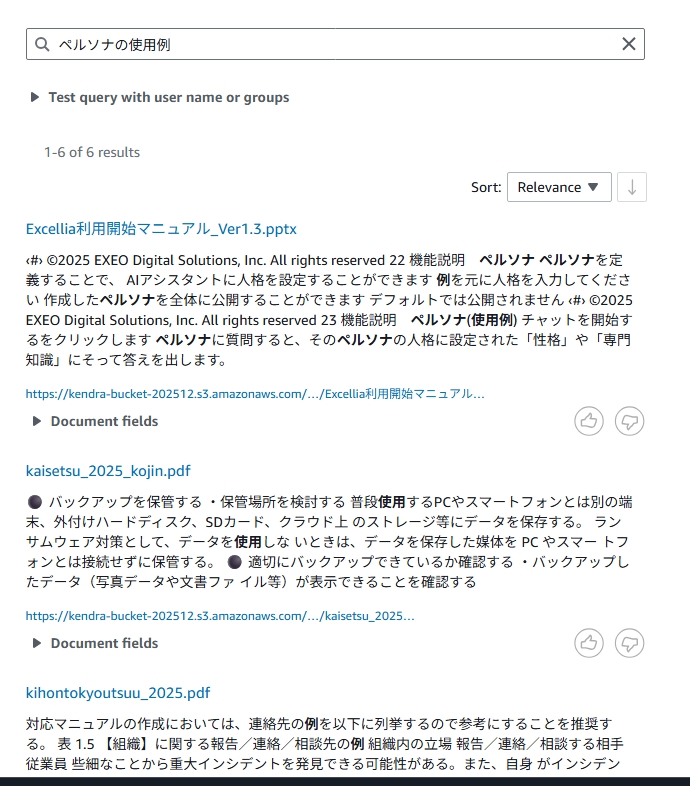
キーワードを完全一致で探す必要がなく、文章形式の質問で検索できるのが特徴です。
ユースケース
Amazon Kendra は以下のような用途で活用できます。
社内ナレッジ検索
マニュアルや設計書、手順書などを横断検索
ヘルプデスク対応の効率化
FAQや過去資料をすぐに参照可能
生成AI(RAG)の検索基盤
Amazon Bedrock と組み合わせて社内データを元に回答を生成
カスタマーサポート向け検索
Salesforce や FAQ データと連携
おわりに
実際に Amazon Kendra を触ってみて、コネクタが豊富に用意されている点や、文書の前処理をほとんど意識せずに利用できる点が印象的でした。また、設定後すぐに自然言語での検索を試すことができるため、検索基盤を比較的簡単に構築できると感じました。
このような特徴から、「まずは社内検索を作りたい」といったケースでは、非常に取り組みやすいサービスだと思います。
一方で、利用料金やカスタマイズ性については、用途や規模によって検討が必要になる場合もありそうです。
社内文書の探しやすさを手軽に改善したい場合には、Amazon Kendra を一度試してみる価値は十分にあると感じました。
