- その他
Code with Claude Tokyo 2026 カンファレンスレポート


2026年6月10日に開催されたAnthropicの開発者カンファレンス「Code with Claude Tokyo」に参加しました。私自身、長らくClaude Codeを使用してきましたが、3月頃にエントリーをし首を長くして待っていたカンファレンスです。
カンファレンス前日に発表されたばかりの「Claude Fable 5/Claude Mythos 5」のお披露目を中心に、エージェント実行基盤「Managed Agents」やClaude Codeの大幅アップデートが発表されました。
カンファレンスでの発表内容、新機能、活用事例、そして後日談まで紹介したいと思います。
https://claude.com/code-with-claude/tokyo
イベントの概要
Code with Claudeは、2025年5月にサンフランシスコで第1回が開催されたAnthropic公式の開発者会議です。2026年はサンフランシスコ、ロンドン、東京の3都市に拡大され、東京は初のアジア開催となりました。
Anthropicは2025年10月に東京にアジア初の拠点を開設しており、Dario Amodei CEOが高市首相と会談するなど、日本市場への本格的な展開に位置づけられるイベントです。
主要な登壇者
キーノートにはClaude Platformエンジニアリング責任者のKatelyn Lesse氏、Research and Labs製品管理責任者のDianne Penn氏が登壇しました。Penn氏はClaude 2からリリースに携わってきた人物で、今回のFable 5について「質が違う」と表現していました。
新モデル「Claude Fable 5/Claude Mythos 5」
キーノート冒頭でKatelyn Lesse氏が「数時間前に第5世代のClaudeをリリースした」と宣言し、会場が沸きました。一般公開されるモデルとしてはAnthropic史上最も高性能とされるFable 5と、安全機構を外した限定提供版のMythos 5の2モデルが披露されました。
性能とベンチマーク
Fable 5はSWE-Bench Proで80.3%を記録しています。これはOpus 4.8の69.2%、GPT-5.5の58.6%を大きく上回る数値です。
SWE-Bench Proとは、AIモデルのソフトウェア開発、主にコーディング能力を測定するためのベンチマークです。従来のベンチマークと比較してより実環境の開発現場に近い、複雑な課題をAIに解決させることによって、AIの限界を測る目的で設計されています。
3つの特徴
Dianne Penn氏は3つの差別化ポイントを挙げていました。
第一に、コーディング性能で、タスクが長く複雑になるほど他モデルとの差が拡大する点があります。
第二に、長時間自律稼働の能力で、数百万トークンと数日間にわたって一貫性を保てるタスク・ホライズンと呼ばれる能力を持っています。
第三に、画像やスクリーンショット、グラフの高精度解析が可能になり、スクリーンショットだけからWebアプリケーションのソースコードを再構築するデモも披露されました。
ハンズオンワークショップ(6本)
公開リポジトリ(anthropics/cwc-workshops)を用いたワークショップが実施されました。内容は以下の通りです。
https://github.com/anthropics/cwc-workshops
- how-we-claude-code:仕様化→デザイン探索→実行時検証
- ship-your-first-managed-agent:agent.pyの7関数を埋めてSREインシデント調査エージェントを構築
- agent-battle:45分でエージェント構成を組みゲームボットの成績を競う対戦形式
- agents-that-remember:メモリ機能の実装
- eval-driven-agent-development:PPTX生成を評価スイートで改良
- production-ready-agent:M&Aリサーチのマルチエージェント構築
「How we Claude Code」3つの技法
Jason Schwartz氏のセッションでは、Anthropic社内でのClaude Code活用技法が3つ紹介されました。
https://claude.com/code-with-claude/tokyo-extended
第一に曖昧さの除去(AskUserQuestionツールで仕様をインタビューする)、第二に計画書はMarkdownではなくHTMLで書く(レビュー精度が向上する)、第三に検証の組み込み(14テスト全パスでもUIが壊れる例が示されました。
計画書をHTMLで書く、というのは数ヶ月前に話題になったものです。これまで仕様書や実装計画書を作成する際は、マークダウン形式が主流でした。先日私が投稿した仕様駆動開発の記事でも全てマークダウン形式で書いています。
これをAnthropicのエンジニアが「HTMLで書いたほうがいい」と宣言して、いま少しずつ状況が変わりつつあります。実際のところ、私はいまでもマークダウン形式で書いていますがHTMLとマークダウン形式で指示した際のLLMの解釈の違いや精度などを個人的に検証してみたいと思います。
https://claude.com/code-with-claude/session/tyo-ext-how-we-claude-code
Fableの読み方は?
正式な読み方がわからなかったのが「Fable」です。公式に「ファブルではなく、フェイブル」と表現されていました。
後日談:Fable 5/Mythos 5の全世界停止
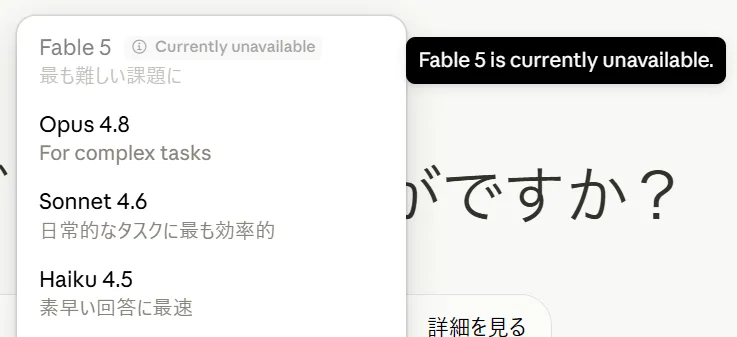
イベントからわずか2日後の6月12日、米国政府が輸出管理指令によりFable 5およびMythos 5への外国籍者アクセス停止を命じました。Anthropicは指令に従い両モデルを全顧客向けに停止しました。
東京で発表されたばかりの主役モデルが、わずか数日で利用不能となる異例の展開でした。米政府側はjailbreak、いわゆる特定コードベースを読みこませて脆弱性を修正させる手法を根拠にしたとされています。

停止は外国人アクセス禁止指令で、私のFableも使えないままです。Anthropic側として外国人を選別できないため事実上の全世界停止となりました。2026年6月15日時点でも復旧時期や条件は未確定のままです。
まとめ
Code with Claude Tokyo 2026は、Anthropicの日本市場への本気度を示すイベントでした。
Fable 5の圧倒的なベンチマーク性能、Managed Agentsによるエージェント運用基盤の成熟、Claude Codeの開発者体験と自律性の強化、そしてSpotify・楽天・Canvaといった実用化の事例は、AIコーディングが「試行」から「本番運用」のフェーズに移行しつつあることを印象づけました。
一方で、Fable 5/Mythos 5停止という展開は、最先端モデルの採用にはテクノロジーだけでなく地政学的リスクの考慮が不可欠であることもわかりました。
プログラミングのスキルがなくても、自分の仕事や専門分野を深く理解している人がAIを使えば、優れたソフトウェアを作れる時代になった、というメッセージがとても印象的でした。これは私自身、Claude CodeやCodexを使用して実感していることです。
AIがコードを書いてくれる今、何を作るべきか・何が正しいかを判断できる現場の知識こそが、開発における最大の武器になると思います。これは、OpusやFableなどモデルの世代が変わっても変わらない本質的な考え方であると思います。
